Introducing Dask Distributed
by Matthew Rocklin
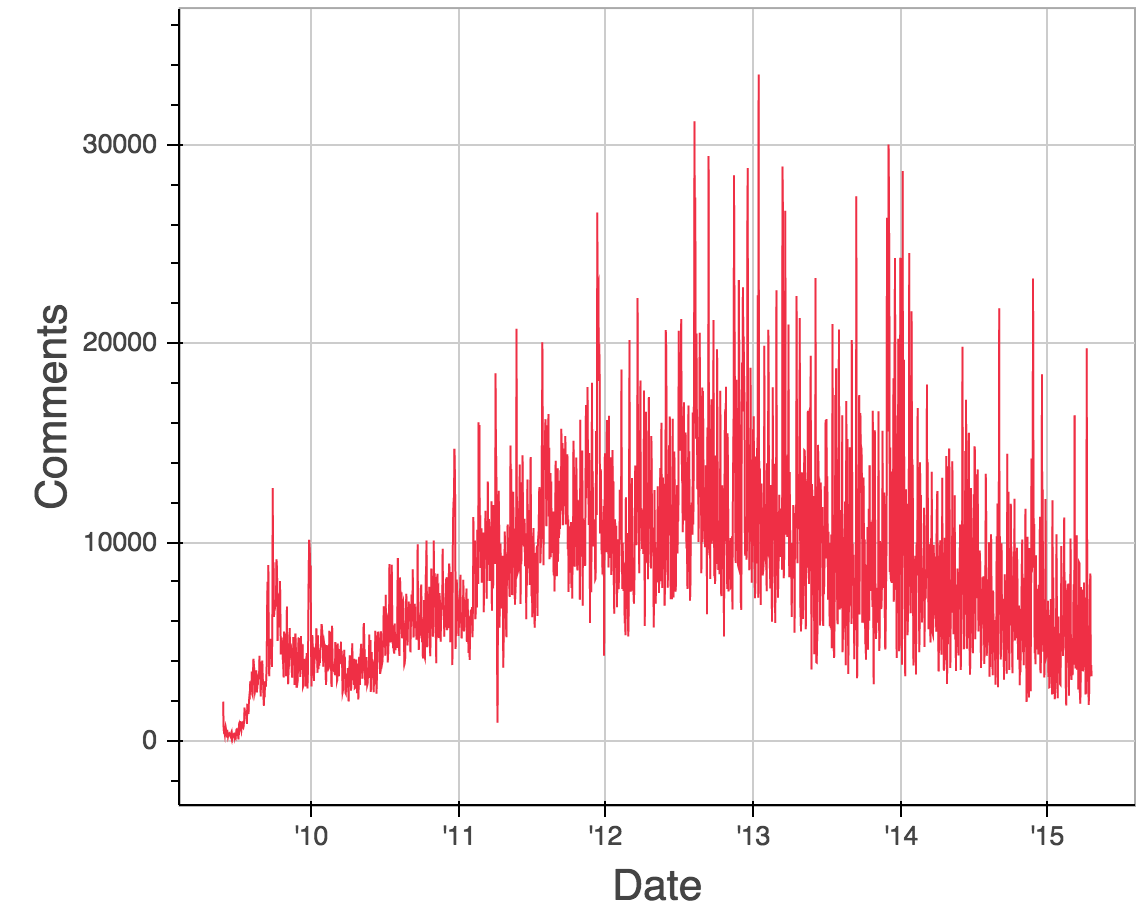
We analyze GitHub data on a cluster using Dask.

The Blaze ecosystem is a set of libraries that help users store, describe, query and process data. It is composed of the following core projects:
We analyze GitHub data on a cluster using Dask.
We use dask.array, a small cluster on EC2, and distributed
We use snakebite and distributed to run Pandas on CSV data in HDFS
Ad-hoc distributed computations with a concurrent.futures interface

tl;dr: We use dask to accelerate parameter searches over machine learning pipelines by naming consistently.
Blaze is a Python library and interface to query data on different storage systems. Blaze works by translating a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze gives Python users a familiar interface to query data living in other data storage systems such as SQL databases, NoSQL data stores, Spark, Hive, Impala, and raw data files such as CSV, JSON, and HDF5. Hive
The scientific Python ecosystem is great for doing data analysis. Packages like NumPy and Pandas provide an excellent interface to doing complicated computations on datasets. With only a few lines of code one can load some data into a Pandas DataFrame, run some analysis, and generate a plot of the results. However, this workflow starts to falter when working with data that's larger than the RAM on your computer. At this point people often move their workflow from a Python based one into some other larger system like Spark or Hadoop. These are great at what they do, but for small problems are a bit overkill
Scale your data, not your process. Welcome to the Blaze ecosystem.
EuroPython 2015, Christine Doig
Going Parallel and Larger-than-memory with Graphs
PyGotham 2015, Blake Griffith
Dask Out of core NumPy and Pandas through Task Scheduling
SciPy 2015, James Crist